Detecção de Fraude em Cartões de Crédito
Uma das principais preocupações das instituições financeiras é com a fraude em cartões de crédito. A utilização de algoritmos de machine learning apenas um pouco melhor que os anteriores já representa uma economia de milhões de Reais.

Neste projeto, iremos abordar o problema das fraudes em cartões de crédito, uma das principais preocupações das instituições financeiras como bancos e fintechs. Em 2020, segundo o Mapa da Fraude, foram registradas 3,5 milhões de transações potencialmente fraudulentas, cerca de 403 tentativas de fraude por hora - nos segmentos de e-commerce, mercado financeiro, vendas diretas e telecomunicações - , isso representou R$ 3,6 bilhões em tentativas de fraude em 2020. (ClearSale, 2021).

Dentre essas fraudes, aquelas envolvendo cartões de crédito são de grande relevância uma vez que a sua não-detecção acarretará em prejuízos consideráveis, tanto para o consumidor quanto para a instituição financeira.
Um outro fator a ser considerado é a quantidade de falsos positivos, ou seja, aquelas vezes em que você tentou fazer uma compra e teve seu cartão bloqueado preventivamente - o que provavelmente gerou estresse e constrangimento.
Ainda que seja desejável reduzir a quantidade de falsos positivos, é preferível (tanto para instituição financeira quanto para o consumidor) que hajam mais falsos positivos do que falsos negativos.
Por todos esses motivos, o investimento na área de detecção de fraudes por meio de Inteligência Artificial vem crescendo a cada ano, representando uma grande oportunidade em Data Science.
Dispondo de grandes volumes de dados como base histórica, um algoritmo de machine learning apenas um pouco melhor que os anteriores já representa uma economia de milhões de Reais. E esse é o desafio, aprimorar cada vez mais o uso de algoritmos visando inibir ou evitar transações fraudulentas.
Sobre os dados
Os dados que usaremos neste projeto foram disponibilizados por algumas empresas europeias de cartão de crédito. O dataset representa as operações financeiras que aconteceram no período de dois dias, onde foram classificadas 492 fraudes em meio a quase 290 mil transações.
Como você pode notar, este é um conjunto de dados extremamente desbalanceado, onde as fraudes representam apenas 0,17% do total.
Outro detalhe interessante é que as features são todas numéricas, e foram descaracterizadas (por problemas ligados à privacidade e segurança). Assim, os nomes das colunas são representados por [V1,V2,V3…,V28]
Na página original dos dados, também é informado que as variáveis passaram por uma transformação conhecida como Análise de Componentes Principais (Principal Component Analysis - PCA).
PCA
A PCA permite a redução da dimensionalidade enquanto mantém o maior número possível de informações. Para conseguir isso, o algoritmo encontra um conjunto novo de recursos - os chamados componentes.
Esses componentes são em número menor ou igual às variáveis originais. No caso deste projeto, os componentes achados pela transformação da PCA são as próprias colunas [V1,V2,V3…,V28].
Objetivos
O objetivo desse projeto é comparar dois modelos de Machine Learning treinados em diferentes condições - com dados desbalanceados, balanceados com over-sampling e balanceados com under-sampling.
Também iremos realizar o comparativo de desempenho de dois dos algoritmos de classificação mais comuns em Machine Learning: Regressão Logística e Árvores de Decisão. Ao todo treinaremos 6 modelos para, ao final do estudo identificarmos qual algoritmo apresentou os melhores resultados nesse cenário.
Não aprofundaremos em todos os conceitos e técnicas utilizadas, se quiser saber mais sobre todo o processo de análise, confira a análise completa no link abaixo:
 virb30
virb30Conhecendo os dados
A primeira etapa do projeto consiste em realizar uma análise exploratória para conhecer os dados que estamos trabalhando e podermos definir as estratégias que utilizaremos, dessa análise conseguimos extrair alguns insights que guiarão os processos seguintes:
- As variáveis
TimeeAmountpossuem seus valores originais, isso nos indica que será necessário ajustar a escala desses atributos para que não impacte no nosso modelo; - Por causa do processo de PCA, evidenciado pela presença das variáveis (V1-V28), não temos mais detalhes sobre o que cada variável significa e nem como elas influenciam na classificação (em fraude ou legítima);
- Também vemos que não há nenhum registro com dados ausentes, nos poupando uma etapa de tratamento.
Separando os conjuntos
Antes de fazermos qualquer tratamento nos dados, é interessante dividir o conjunto em dois subconjuntos: treino e teste. Uma recomendação geral é que o modelo só tenha conhecimento dos dados de teste após treinado e validado, com isso, além de conseguirmos simular uma situação real onde o modelo deverá ser capaz de classificar dados novos/desconhecidos, evitamos que o modelo seja "viciado" e funcione apenas para os dados nos quais foi treinado.
Analisando nossos dados
O gráfico, Figura 1, deixa claro o desbalanceamento do dataset, com apenas 0,17% do total de registros sendo classificados como fraude.

Portanto será necessário balancearmos os dados antes de treinar nosso modelo de classificação.
Preparação dos dados
De modo a conseguirmos comparar o desempenho dos modelos que utilizam o mesmo algoritmo, utilizaremos duas técnicas de balanceamento nos dados de treino:
- over-sampling: nessa técnica, os dados da classe minoritária (no caso, fraudes) são replicados até que atinjam a mesma quantidade da classe majoritária, por exemplo se temos 50 registros da classe 1 e 10 da classe 2 ao final do balanceamento teremos 50 registros de cada classe;
- under-sampling: essa técnica é o processo oposto da técnica anterior, ou seja, exemplos da classe majoritária são removidos, aleatoriamente, até que ambas fiquem com a mesma quantidade, se utilizarmos as mesmas condições do exemplo anterior - 50 registros da classe 1 e 10 da classe 2 - ao final do balanceamento teremos 10 registros de cada classe.
Dividir entre treino e validação
Antes de realizarmos qualquer tratamento nos dados, é interessante dividirmos nosso subconjunto (lembram-se que já fizemos uma divisão no início da análise?) em dois novos: treino e validação. Os novos conjuntos ficaram com os seguintes tamanhos:
- Treino: 181564
- Validação: 60522
- Teste: 42721
Padronizar dados
Como vimos anteriormente, as variáveis Time e Amount estão em escala diferente das demais e isso pode prejudicar o treinamento do nosso modelo, portanto precisaremos padronizá-las. Como a variável Amount possui outliers utilizaremos a classe StandardScaler disponível no pacote scikitlearn.
Nesse momento a padronização deverá ser realizada somente no dataset de treino.
A classe StandardScaler além de transformar as variáveis, também armazenará os estados da transformação, dessa maneira, quando formos validar e testar o modelo, o novo conjunto de dados passará pela mesma transformação, utilizando os mesmos valores que foram "treinados" pelo conjunto de treino, evitando assim potenciais "vícios".
Balanceamento dos dados
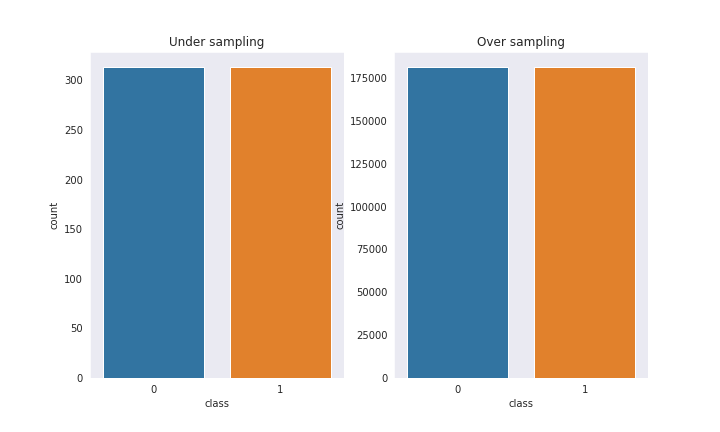
Agora que nossos dados de treino estão padronizados, e conforme citado anteriormente, iremos balancear os dados de duas maneiras: under-sampling e over-sampling ao final do processo teremos dois conjuntos de dados da seguinte maneira:
- under-sampling: 313 registros de cada classe
- over-sampling: 181251 registros de cada classe
Podemos ver nos gráficos da Figura 2 que agora nossos dados estão balanceados e podemos prosseguir para o treinamento do modelo.
Modelo de Machine Learning
Com os dados balanceados podemos seguir com a construção dos nossos modelos. Como estamos lidando com um problema de classificação binária (ou seja o alvo pode assumir apenas 2 valores - 0 ou 1) e conforme citamos no início desse artigo, iremos realizar um comparativo entre dois modelos: regressão logística e árvores de decisão.
Ambos os modelos serão treinados da seguinte maneira: 1) utilizando os dados originais, 2) com dados balanceados com under-sampling e 3) com dados balanceados com over-sampling.
Em seguida iremos comparar o desempenho dos modelos treinados com mesmo algoritmo mas com balanceamentos diferentes e, por fim, realizaremos a comparação de qual dos 6 modelos apresentou melhores resultados.
Modelo de Regressão Logística
O modelo de regressão logística utiliza a função sigmoide e mapeia os valores de saída no intervalo [0, 1], sendo, portanto, o mais utilizado em problemas de classificação binária, como: detecção de spam, tumor maligno/benigno, fraudes etc.
Modelo de Árvore de Decisão
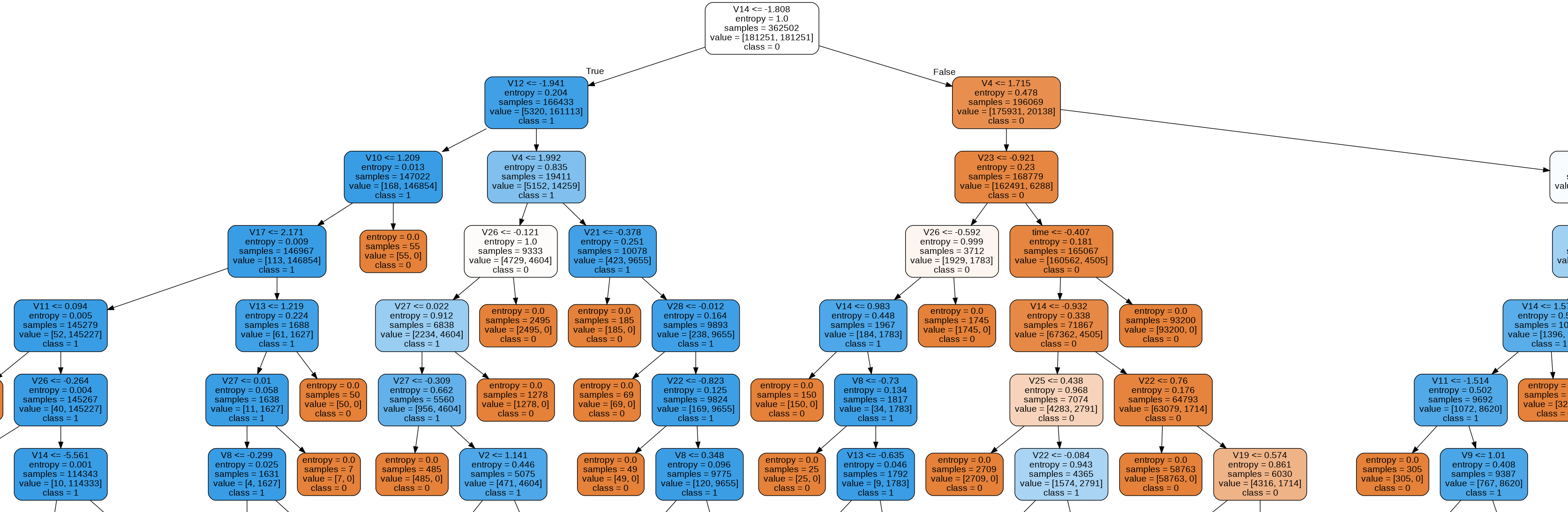
O algoritmo de Árvore de Decisão é mais intuitivo para humanos, uma vez que faz a avalia propriedades e, com base em critérios calculados durante o treino, toma sucessivas decisões sobre qual caminho seguir (direita ou esquerda) até que não haja mais decisões a tomar. Para ficar mais claro a Figura 3 mostra parte de uma árvore de decisão.
Avaliando o modelos
Para avaliar nossos modelos, utilizaremos, com métrica de avaliação, os indicadores: precision, recall e f1-score.
precision nos informa a quantidade proporcional de identificações positivas feitas corretamente, ou seja, dentre as previsões marcadas como positivo, qual foi o percentual de acerto do algoritmo, podemos resumir precision com a equação:
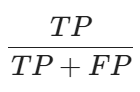
recall nos diz a proporção de positivos encontrados corretamente, ou seja, dos dados reais positivos, qual proporção deles foi realmente marcado como positivo, e é dado pela equação:
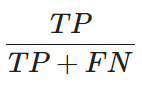
O F1-score é a média harmônica entre precision e recalle nos dá uma boa ideia do desempenho do nosso algoritmo. É obtido pela equação:
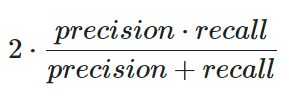
Onde:
- TP = true positive (previsões positivas corretas)
- FP = false positive (previsões positivas incorretas)
- FN = false negative (previsões negativas incorretas)
- TN = true negative (previsões negativas corretas)
Outra métrica interessante, e que utiliza-se dos conceitos acima abordados é a AUC ROC, que podem ser definidas como:
- ROC ou Receiver Operation Characteristic traça uma curva baseada nas taxas de verdadeiro positivo e falso positivo.
- AUC ou Area Under the Curve é uma métrica que traduz a curva ROC em um número através do cálculo, como o nome sugere, da área sob a curva ROC.
Utilizaremos como métrica para nossa comparação, principalmente os índices AUC ROC e recall.
Avaliando o modelo de regressão
Para os cenários de treino propostos obtivemos os seguintes resultados para o modelo de Regressão Logística, a Figura 4 mostra, de forma visual, esses resultados:
Dataset Original
- Acurácia global: 99,93%
- Recall: 69,52%
- AUC ROC: 84,75%
O recall nos diz que apenas 69,52% das previsões de fraude foram feitas corretamente, o que significa uma taxa de aproximadamente 31% de falsos positivos, aliado à acurácia global de 99,93% temos um forte indício de que esse modelo está com overfitting.
Under-sampling
- Acurácia global: 96,86%
- Recall: 91,43%
- AUC ROC: 94,15%
Quando utilizamos dados balanceados com under-sampling notamos uma melhora no recall, ou seja, 91,43% das previsões de fraude foram corretas - isso provoca uma redução no número de falsos positivos.
Over-sampling
- Acurácia global: 97,71%
- Recall: 89,52%
- AUC ROC: 93,62%
O modelo de regressão treinado com o dataset balanceado em over-sampling apresentou resultados semelhantes aos anteriores. porém ligeiramente piores.
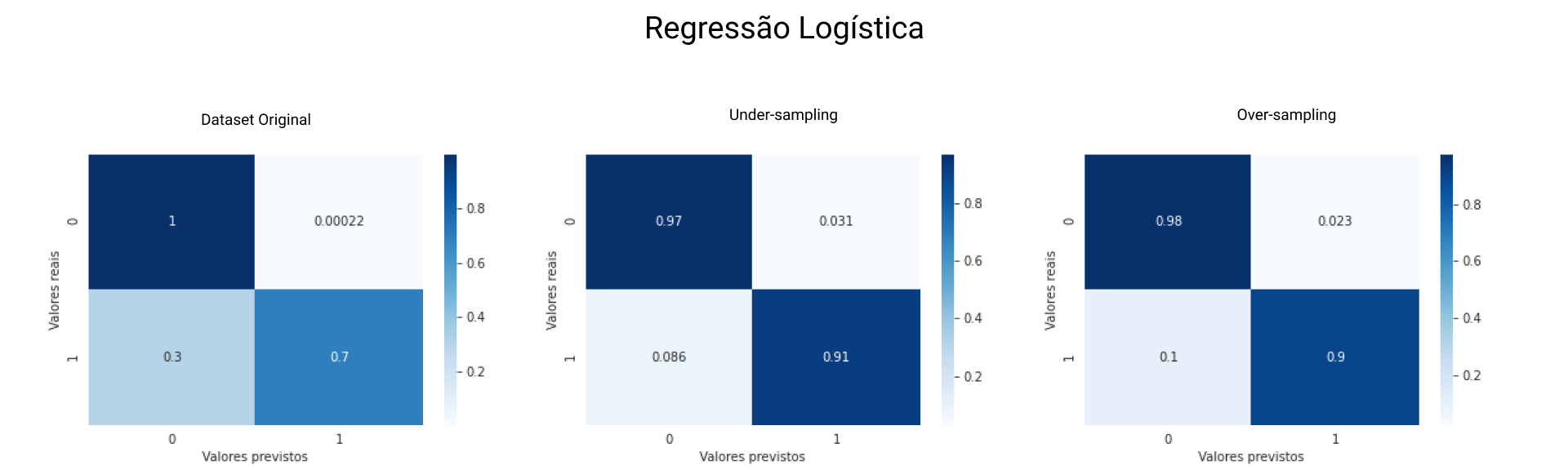
Notamos, portanto, que, para esse dataset, o modelo de regressão tem melhor desempenho com menos dados e dados reais (não fabricados).
Avaliando o modelo de Árvore
Para facilitar a comparação apresentaremos os resultados da mesma maneira que fizemos para o modelo de regressão e a Figura 5 contém a representação gráfica dos resultados:
Dataset Original
- Acurácia global: 99,92%
- Recall: 80,95%
- AUC ROC: 90,45%
Esses resultados revelam que, para dados desbalanceados, o modelo de árvore de decisão é melhor que o modelo de regressão - recall de 80,95%, em contrapartida, a acurácia global de quase 100% é um forte indício de overfitting.
Under-sampling
- Acurácia global: 87,15%
- Recall: 90,48%
- AUC ROC: 88,81%
Apesar de ter apresentado menor índice AUC ROC, o modelo de árvore de decisão treinado com apresentou melhores resultados de recall.
Over-sampling
- Acurácia global: 99,91%
- Recall: 77,14%
- AUC ROC: 88,54%
Já o modelo de árvore de decisão treinado com dados balanceados em Over-sampling apresentou resultados piores até que quando treinado com dados desbalanceados.
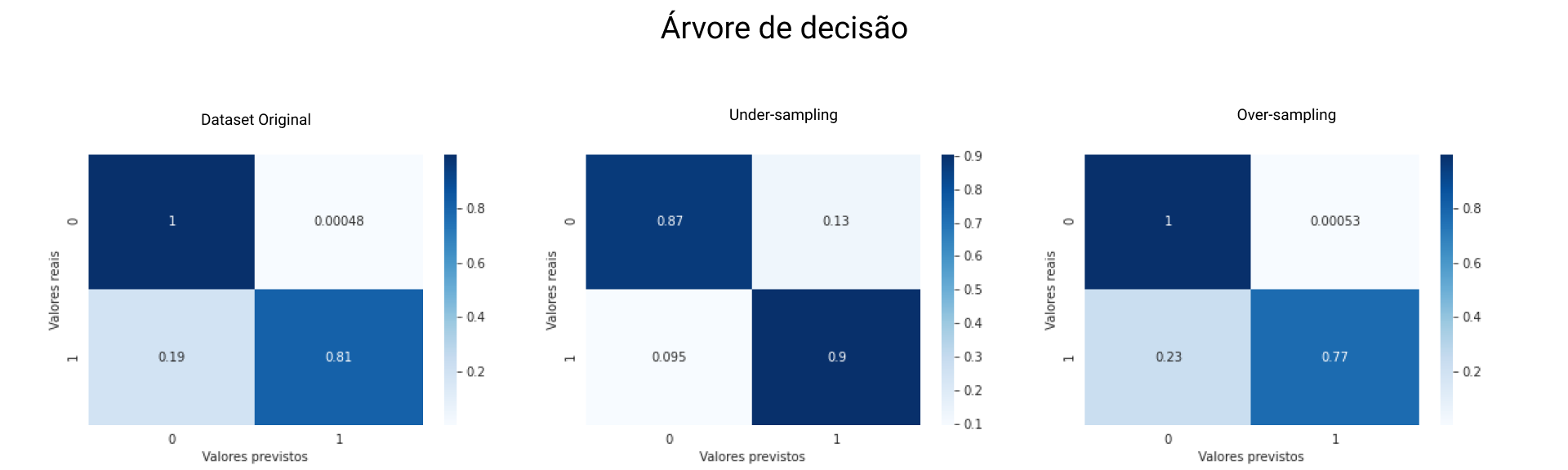
Esses resultados nos mostram que o modelo de árvore de decisão é menos eficiente quando o volume de dados é maior, também nos mostra que esse modelo é menos suscetível a dados desbalanceados se comparado com o modelo de regressão.
Conclusão
Nessa análise comparamos o desempenho de dois modelos de classificação baseados em algoritmos diferentes - Regressão Logística e Árvore de Decisão - aplicados ao problema de detecção de fraudes em transações de cartão de crédito utilizando um mesmo conjunto de dados.
Consideramos principalmente as métricas recall e AUC ROC para nosso comparativo, uma vez que são esses indicadores que melhor representam a taxa de acerto (fraudes detectadas corretamente), os resultados foram resumidos e podem ser vistos na Tabela 1.
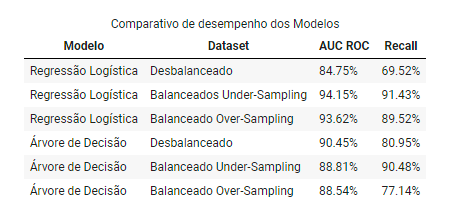
A tabela acima nos revela características importantes com relação ao nosso cenário (problema e dados):
- O algoritmo de regressão logística apresentou melhor desempenho com o dataset balanceado através da técnica de under-sampling (com um menor volume de amostras).
- O algoritmo de árvore de decisão apresentou melhor desempenho em relação a taxa de acertos de transações fraudulentas (
recall), quando treinado utilizando um dataset balanceados com under-sampling (menor volume de amostras). - O modelo de árvore de decisão apresentou melhor desempenho - comparado ao de regressão - quando os dados estavam desbalanceados, mostrando mais robustez desse algoritmo em situações semelhantes.
No cenário de detecção de fraudes em cartão de crédito esperamos obter: menor número de falsos positivos (melhor experiência do cliente) e menor número de falsos negativos (mais segurança tanto para a instituição quanto para o cliente), logo, o modelo recomendado para esse cenário é o de Regressão Logística treinado com o dataset balanceado com under-sampling.
Essa análise também nos mostrou que, apenas com a realização do tratamento adequado nos dados é possível melhorar o desempenho de modelos de Machine Learning, dispensando a necessidade de desenvolver um novo algoritmo ou realizar ajustes finos para atingir resultados satisfatórios. No entanto com um bom tunning nos parâmetros, aliado a um bom conjunto de dados é possível obtermos modelos cada vez melhores e mais precisos.