Churn Prediction - Prevendo evasão de clientes de uma empresa
Churn prediction - como Machine Learning pode ajudar sua empresa a reter clientes.


Churn ou Churn rate, é uma métrica que representa a taxa de evasão de clientes em determinado período de tempo, ou seja, quanto menor o Churn Rate, melhor.
Outra métrica bastante relevante e derivada dessa taxa, é o Churn de Receita ou Monthly Recurring Revenue (MMR) Churn que representa o total de receita perdida em razão desses cancelamentos.
O que fazer com essa informação?
Através da taxa de churn (ou churn rate) e sua análise ao longo do tempo é possível identificar se há algum problema que deve ser atacado de modo a evitar a evasão de clientes, por exemplo se há algum aspecto do produto que têm desagradado os usuários a ponto de cancelar o serviço.
Como utilizar essa informação?
Churn também pode ser utilizado para identificar potenciais cancelamentos com antecedência, possibilitando a tomada de ações para reter tais clientes.
Para empresas que querem crescer, é necessário investir para adquirir novos clientes. Cada vez que um cliente cancela um serviço isso representa uma perda de investimento significativa, consequentemente mais tempo e esforço serão necessários para repor esse cliente.
Ser capaz de prever quando um cliente está propenso a cancelar e pró-ativamente oferecer incentivos para que ele fique pode oferecer grandes economias para um negócio.
O que vamos fazer?
Nesse projeto iremos construir um modelo de Machine Learning utilizando o algoritmo XGBoost e compararemos seu desempenho com um modelo baseado em Árvore de Decisão.
Aquisição dos dados
Os dados utilizados neste projeto foram originalmente disponibilizados na plataforma de ensino da IBM Developer, e tratam de um problema típico de uma companhia de telecomunicações. O dataset completo pode ser encontrado neste link.
Apesar de não haver informações explícitas disponíveis, os nomes das colunas permitem um entendimento a respeito do problema.
Análise Exploratória
Como todo projeto de Data Science começamos realizando a análise exploratória dos dados de modo a identificar com o que estamos lidando: quantas e quais são as variáveis e seus respectivos tipos, quantos registros o conjunto de dados possui, se temos dados ausentes e quais tratamentos precisaremos realizar.
Após a análise do nosso dataset chegamos ao seguinte cenário:
- Nosso dataset possui 7043 registros;
- Nossa variável alvo é representada pela coluna
Churne possui menos amostras de cancelamento do que não cancelamento (que era esperado); - As colunas
tenure,MonthlyChargeseTotalChargessão numéricas, as demais são categóricas; - As variáveis categóricas possuem, no máximo 4 categorias possíveis;
- A coluna
TotalChargespossui 11 registros com o valor " " (texto vazio).
Tratamento dos dados
Aplicaremos os passos a seguir para a transformação dos dados de modo que fiquem preparados para utilização no modelo. Essas mesmas etapas deverão ser seguidas tanto nos conjuntos de treino quanto nos de teste:
- Codificar as variáveis categóricas utilizando OneHotEncoding (se você não está familiarizado com esse termo, confira esse artigo);
- Padronizar as variáveis numéricas de modo que elas fiquem numa mesma escala;
Como nossos dados estão desbalanceados, precisaremos balanceá-los antes de treinar o modelo, para isso utilizaremos a técnica de Under sampling - que elimina alguns registros da classe majoritária até que o conjunto esteja balanceado. Faremos isso apenas com o conjunto de treino.
Escolhendo um modelo
Como mencionamos anteriormente iremos utilizar o XGBoost para essa análise, nesse artigo o autor compara 4 algoritmos de Machine Learning: Árvores de Decisão, Random Forest, Gradient Boosted Machine Tree “GBM” e XGBoost, como resultado, o XGBoost foi o que apresentou melhor desempenho.
Treinando e avaliando o modelo
Com o modelo escolhido podemos continuar para as etapas de treinamento e avaliação do modelo.
O treinamento consiste em passar os dados de treino para o pipeline, o pipeline é responsável por realizar as transformações dos dados e treinar fit o modelo.
pipeline = Pipeline([
('feature_transformer', features_transformer),
('classifier', model)
])
pipeline.fit(X_train_balanced, y_train_balanced)Com o modelo treinado passamos os dados de validação para realizar as previsões
y_pred = pipeline.predict(X_val)
y_proba = pipeline.predict_proba(X_val)Com as previsões realizadas é possível avaliar o desempenho do modelo, em nosso caso estamos utilizando a métrica recall, ou seja, taxa de previsões de churn positivo (clientes que cancelaram o serviço) realizadas corretamente pelo algoritmo. Os resultados podem ser vistos na imagem abaixo:
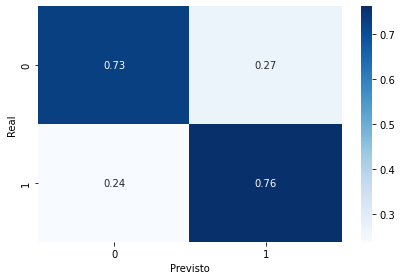
Obtivemos uma taxa de 76% de acerto para churn = 1 (sim)
Melhorando o Modelo
Com uma primeira versão do modelo criada, vamos tentar melhorar seu desempenho com alguns ajustes nos parâmetros (ou fine tuning). Iremos contar com a ajuda do GridSearch para descobrirmos os melhores parâmetros.
# importar pacotes
from sklearn.model_selection import GridSearchCV
# definir parâmetros que serão avaliados
parameters = {
'learning_rate': [0.01, 0.05, 0.1],
'n_estimators': [100, 500],
'max_depth': [4, 5, 6],
'eta': [0.01, 0.05, 0.1],
'subsample': [0.9],
'colsample_bytree': [0.2]
}
clf = GridSearchCV(model, parameters)
X_train_transformed = features_transformer.fit_transform(X_train_balanced)
clf.fit(X_train_transformed, y_train_balanced)
print("Melhor: {} usando {}".format(clf.best_score_, clf.best_params_))O GridSearch sugere que utilizemos:
colsample_bytree = 0.2eta = 0.01learning_rate = 0.05max_depth = 4n_estimators = 100subsample = 0.9
Treinaremos novamente nosso modelo, dessa vez com esses parâmetros e realizaremos as previsões:
# novo modelo com tunning
model_tuned = XGBClassifier(
learning_rate=0.05,
n_estimators=100,
max_depth=4,
gamma=1,
subsample=0.9,
colsample_bytree=0.2,
objective='binary:logistic',
eta=0.01,
random_state=42,
)
# replace pipeline model
pipeline.steps[1] = ('classifier', model_tuned)
# treinar modelo
pipeline.fit(X_train_balanced, y_train_balanced)
# realizar previsões
y_pred = pipeline.predict(X_val)
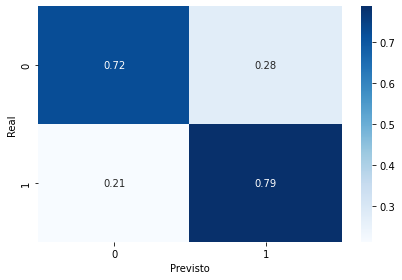
y_proba = pipeline.predict_proba(X_val)Com o novo modelo treinado obtivemos um desempenho um pouco melhor: 79% de recall:
Conclusão
Nosso modelo apresentou melhor desempenho do que um modelo baseado em Árvore de decisão, conforme exposto nesse artigo.
Vimos ainda que é possível melhorar o desempenho dos modelos apenas realizando o tunning adequado nos seus parâmetros. No entanto, a melhora mais significativa foi obtida com o tratamento adequado nos dados e na escolha do modelo.
Vale ressaltar ainda que como nosso conjunto de dados contém dados do usuário somente - e não possui dados referentes à experiência do usuário, por exemplo número de reclamações ou solicitações de suporte - não foi possível realizar nenhuma engenharia que nos desse mais informações e possivelmente melhorar ainda mais o desempenho.
Por fim, podemos dizer que nosso modelo obteve um desempenho satisfatório ao conseguir prever corretamente aproximadamente 80% dos casos de churn.
O Projeto
 virb30
virb30Referências

 Resultados Digitais
Resultados Digitais